3.2. 가설
가설(Hypothesis)이란 어떤 사실을 설명하거나 증명하기 위한 가정으로 두 개 이상의 변수의 관계를 검증 가능한 형태로 기술하여 변수 간의 관계를 예측하는 것을 의미한다.
- 연구가설(Research Hypothesis) : 연구자가 검증하려는 가설로 귀무가설을 부정하는 것으로 설정한 가설
- 귀무가설(Null Hypothesis) : 처음부터 버릴 것을 예상하는 가설
- 대립가설(Alternative Hypothesis) : 귀무가설과 반대되는 가설
3.2.1. 머신러닝에서의 가설
머신러닝에서의 가설은 독립 변수(X)와 종속 변수(Y) 간의 관계를 가장 잘 근사(Approximation)시키기 위해 사용된다.
- 단일가설(Single Hypothesis) - h : 입력을 출력에 매핑하고 평가하고 예측하는 데 사용할 수 있는 단일 시스템
- 가설집합(Hypothesis Set) - H : 출력을 입력에 매핑하기 위한 가설 공간(Hypothesis Space), 모든 가설을 의미
가설은 회귀 분석과 같은 알고리즘을 통해 최적의 가중치와 편향을 찾는 과정을 진행하게 되며, 학습이 진행될 때마다 기울기와 편향이 지속해서 바뀌게 된다.
학습이 된 결과를 모델(Model)이라 하고, 이 모델을 통해 새로운 입력에 대한 결괏값을 예측(Prediction)한다.
3.2.2. 통계적 가설 검정 사례
- t-검정(t-test)
- 쌍체 t-검정(paires t- test) : 동일한 항목 또는 그룹을 두 번 테스트할 때 사용 예) 동일 집단에 대한 약물 치료 전후 효과 검정
- 비쌍체 t-검정(unpaired t-test) : 등분산성(homoskedasticity)을 만족하는 두 개의 독립적인 그룹 간의 평균을 비교하는 데 사용 예) 서울과 인천의 무작위로 선택된 참가자 1000명의 평균 통근 거리 비교
여기서, 비쌍체 t-검정의 가설은 쌍체 t-검정의 가설과 동일하다.
- 귀무가설$(H_0)$ : 두 모집단의 평균 사이에 유의한 차이가 없다.
- 대립가설$(H_1)$ : 두 모집단의 평균 사이에 유의한 차이가 있다.
하지만 머신러닝에 통계적 가설을 적용한다면 비쌍체 t-검정을 사용해야한다. 독립 변수와 종속 변수 사이에 유의미한 차이가 있는지 검정하는데, 이때 변수들의 데이터는 독립항등분포(independent and identically distributed)를 따른다.
3.3. 손실함수
손실 함수(Loss Function) : 단일 샘플의 실젯값과 예측값의 차이가 발생했을 때 오차가 얼마인지 계산하는 함수 인공 신경망은 실젯값과 예측값을 통해 계산된 오찻값을 최소화해 정확도를 높이는 방법으로 학습이 진행된다. 손실함수는 목적함수(Objective function), 비용함수(Cost Function)라고 부르기도 한다.
- 목적 함수 : 함숫값의 결과를 최댓값 또는 최솟값으로 최적화하는 함수
- 비용 함수 : 전체 데이터에 대한 오차를 계산하는 함수
→ 손실함수 < 비용함수 < 목적함수
3.3.1. 제곱 오차
평균 제곱 오차(Mean Squared Error, MSE) 방법은 제곱 오차(Squared Error, SE)와 오차 제곱합(Sum of Squared for Error, SSE)을 활용한다.
$$ SE = {(Y_i-\hat{Y_i})}^2 $$
3.3.2. 오차 제곱합
오차 제곱합(Sum of Squared for Error, SSE)은 제곱 오차를 모두 더한 값을 의미한다. 제곱 오차는 각 데이터의 오차를 의미하므로 가설 또는 모델 자체가 얼마나 정확히 예측하는지는 알 수 없다. 그러므로 모든 제곱 오차를 더해 하나의 값으로 만들어 가설이나 모델을 평가할 수 있다.
$$ SSE = \sum^n_{i=1}{(Y_i-\hat{Y_i})}^2 $$
3.3.3. 평균 제곱 오차
평균 제곱 오차(Mean Squared Error, MSE)방법은 단순하게 오차 제곱합에서 평균을 취하는 방법이다. 데이터가 많아질수록 오차 제곱합도 동일하게 커지므로, 평균값을 사용하지 않는 경우 오차가 많은 것인지 데이터가 많은 것인지 구분하기가 어려워진다. 따라서 모든 데이터의 개수만큼 나누어 평균을 계산한다.
$$ MSE = {1\over{n}}\sum^n_{i=1}{(Y_i-\hat{Y_i})}^2 $$
3.3.4. 교차 엔트로피
1~3은 연속형 변수에 사용되는 손실함수이다.
이산형 변수에는 교차엔트로피(Cross-Entropy)가 손실함수로 사용된다.
실제 확률분포를 $y$, 예측된 확률분포를 $\hat{y}$라고 하면 교차엔트로피의 수식은 아래와 같다.
$$ CE(y,\hat{y}) = -\sum_{j}y_j\log\hat{y_i} $$
3.4. 최적화
최적화(Optimization) : 목적 함수의 결괏값을 최적화하는 변수를 찾는 알고리즘 손실 함수의 값이 최소가 되는 변수를 찾는다면 새로운 데이터에 대해 더 정교한 예측을 할 수 있다. 최적화 알고리즘은 실젯값과 예측값의 차이를 계산해 오차를 최소로 줄일 수 있는 가중치와 편향을 계산한다.
최적의 가중치에는 오차가 가장 적으며, 최적의 가중치에서 멀어질수록 오차가 커진다. → 즉, 가중치와 오차의 그래프에서 기울기가 0에 가까워질 때 최적의 가중치를 갖는다.
3.4.1. 경사하강법
경사하강법(Gradient Descent)이란 함수의 기울기가 낮은 곳으로 계속 이동시켜 극값에 도달할 때까지 반복하는 알고리즘이다.
$$ W_0=Initial Value\\W_{i+1} = W_i-\alpha{\nabla{f(W_i)}} $$
3.4.2. 학습률
가중치를 갱신할 때 $\alpha$를 곱해 가중치 결과를 조정하는 것을 확인했다. 머신러닝에서는 $\alpha$값을 확습률(Learning rate)라고 한다. 초깃값($W_0$)을 임의의 값으로 설정해주듯이 이 학습률($\alpha$)도 임의의 값으로 설정한다.
3.4.3. 최적화 문제
초깃값 또는 학습률을 너무 낮거나 높게 잡으면 최적의 가중치를 찾는 데 오랜 시간이 걸리거나, 그래프가 발산하여 아예 값을 찾지 못할 수 있다. 예를 들어 가중치와 오차가 4차 함수와 같은 그래프의 형태를 보이면 최솟값이 아닌 극솟값에서 가중치가 결정될 수 있다. 또한, 안장점이 존재하는 함수에서도 적절한 가중치를 찾을 수 없다.
학습에 사용하는 데이터의 형태나 가설, 손실 함수 등에 따라 적합한 최적화 알고리즘을 사용해야한다. 앞서 설명한 극솟값과 안장점 문제 등에 강건한 기법도 존재한다. 최적화 알고리즘은 경사 하강법 이외에도 모멘텀(Momentum), Agagrad(Adaptive Gradient), Adam(Adaptive Moment Estimation) 등이 있다.
3.5. 데이터세트와 데이터로더
데이터세트는 데이터의 집합을 의미하며, 입력값(X)과 결괏값(Y)에 대한 정보를 제공하거나 일련의 데이터 묶음을 제공한다. 데이터세트의 구조는 일반적으로 데이터베이스의 테이블과 같은 형태로 구성되어 있다.
→ 다양한 데이터를 활용하기 위해서 전처리 단계가 필요한 경우도 있기 때문에 모듈화, 재사용성, 가독성을 떨어뜨릴 수 있다. 따라서 이러한 현상을 방지하고 코드를 구조적으로 설계할 수 있도록 데이터세트와 데이터로더를 사용한다.
3.5.1. 데이터세트
데이터세트는 학습에 필요한 데이터샘플을 정제하고 정답을 저장하는 기능을 제공한다.
#데이터세트 클래스 기본형
class Dataset:
def __init__(self, data, *arg, **kwargs):
self.data = data
def __getitem__(self,index):
return tuple(data[index] for data in data.tensors)
def __len__(self):
return self.data[0].size(0)
- 초기화 메서드(__init__)
입력된 데이터의 전처리 과정을 수행하는 메서드이다. 새로운 인스턴스가 생성될 때 학습에 사용될 데이터를 선언하고, 학습에 필요한 형태로 변형하는 과정을 진행한다.
- 호출 메서드(__getitem__)
학습을 진행할 때 사용되는 하나의 행을 불러오는 과정으로 볼 수 있다. 입력된 index에 해당하는 데이터 샘플을 불러오고 반환한다.
- 길이 반환 메서드(__len__)
학습에 사용된 전체 데이터세트의 개수를 반환한다.
3.5.2. 데이터로더
데이터로더는 데이터세트에 저장된 데이터를 어떠한 방식으로 불러와 활용할지 정의한다.
- 배치 크기(batch_size)
전체 데이터 세트에서 배치 크기만큼 데이터 샘플을 나누고, 모든 배치를 대상으로 학습을 완료하면 에폭 1회
- 데이터 순서 변경(shuffle)
모델이 데이터 간의 관계가 아닌, 데이터의 순서로 학습되는 것을 방지하고자 수행하는 기능 데이터 샘플과 정답의 매핑 관계는 변경되지 않으며, 행의 순서를 변경하는 개념
- 데이터 로드 프로세스 수(num_workers)
데이터를 불러올 때 사용할 프로세스의 개수 학습을 제외한 코드에서는 데이터를 불러오는 데 시간이 가장 오래 걸리므로 이를 최소화하고자 데이터로드에 필요한 프로세스의 수를 늘릴 수 있다.
3.6. 모델/데이터세트 분리
파이토치의 모델은 인공 신경망 모듈을 활용해 구현된다. 모델 구현은 신경망 패키지의 모듈(Module) 클래스를 활용한다.
3.6.1. 모듈 클래스
모듈클래스는 초기화 메서드와 순방향 메서드를 재정의하여 활용한다. 모듈 클래스를 통해 모델을 정의해 모델 객체를 호출하는 순간 순방향 메서드가 실행된다.
#모듈 클래스 기본형
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
return x
- 초기화 메서드(__init__)
신경망에 사용될 계층을 초기화
- 순방향 메서드(forward)
모델이 어떤 구조를 갖게 될지를 정의 초기화 메서드에서 선언한 모델 매개변수를 활용해 신경망 구조를 설계
초기화 메서드에서 super 함수로 부모 클래스를 초기화했으므로 역방향 연산은 정의하지 않아도 된다.
3.6.2. 비선형 회귀(예제 3.35~3.40)
csv 파일을 읽어오기 위해서는 import pandas as pd를 해야한다.
3.6.3. 모델 평가(예제 3.41~)
모델의 가중치와 편향을 확인해 이론적으로 학습이 잘 진행된 것은 알 수 있다. 학습에 사용되지 않은 임의의 데이터를 모델에 입력해 결과를 확인해보자.
#모델 평가
with torch.no_grad():
model.eval()
inputs = torch.FloatTensor([1**2,1],[5**2,5],[11**2,11]).to(device)
outputs = model(inputs)
print(outputs)
#모델 저장
torch.save(model,"../models/model.pt")
torch.save(model.state_dict(),"../models/model_state_dict.pt")
모델을 평가 모드 eval()로 변경하지 않으면 일관성없는 추론 결과를 반환하므로 평가 시 항상 선언하자!!
3.6.4. 데이터세트 분리(예제 3.44)
머신러닝에서 사용되는 전체 데이터세트는 두 가지 혹은 세 가지로 나눌 수 있다.
전체 데이터세트는 훈련용 데이터, 테스트 데이터로 분류되고, 더 세분화하면 검증용 데이터까지 분리한다.
(일반적으로 6:2:2 혹은 8:1:1 비율로 데이터세트를 나눈다.)
- 훈련용 데이터
모델을 학습하는 데 사용되는 데이터세트
- 검증용 데이터
학습이 완료된 모델을 검증하기 위해 사용되는 데이터세트
- 테스트 데이터
검증용 데이터를 통해 결정된 성능이 가장 우수한 모델을 최종 테스트하기 위한 목적으로 사용되는 데이터 세트
3.7. 모델 저장 및 불러오기
모델 학습은 오랜 시간이 소요되는 작업이므로 학습 결과를 저장하고 불러와 활용할 수 있어야 한다. 파이토치의 모델은 직렬화(Serialize)와 역직렬화(Deserialize)를 통해 객체를 저장하고 불러올 수 있다.
모델을 저장하려면 파이썬의 피클(pickle)을 활용해 파이썬 객체 구조를 바이너리 프로토콜(Binary Protocols)로 직렬화한다.
모델을 불러오려면 저장된 객체 파일을 역직렬화해 현재 프로세스의 메모리에 업로드한다.
3.7.1. 모델 전체 저장/불러오기(예제 3.47)
불러올 때에는 동일한 형태의 클래스가 선언되어 있어야한다.
→ CustomModel 클래스를 선언해야한다!
#모델 저장 함수
torch.save(model,path)
#모델 불러오기 함수
model = torch.load(path, map_lacation)
#모델 구조 확인
import torch
from torch import nn
class CustomModel(nn.Module):
pass
device = "mps" if torch.backends.mps.is_available() else "cpu"
model = torch.load("../models/model.pt", map_location = device)
print(model)
3.7.2. 모델 상태 저장/불러오기
모델 전체를 저장하려면 많은 용량이 필요하므로 state_dict를 통해 상태만 저장할 수 있다.
불러올 때에는 동일한 형태의 클래스가 선언되어 있어야한다.
→ CustomModel 클래스를 선언해야한다!
#모델 상태 저장
torch.save(model.state_dict(),"../models/model_state_dict.pt")
#모델 상태 불러오기
class CustomModel(nn.Module):
pass #구현은 원래와 같이 되어있어야함.
model_state_dict = torch.load("../models/model_state_dict.pt", map_location=device)
model(load_state_dict(model_state_dict)
3.7.3. 체크포인트 저장/불러오기(예제 3.51, 예제3.52)
체크포인트는 학습 과정의 특정 지점마다 저장하는 것을 의미한다.
데이터의 개수가 많거나 깊은 구조의 모델을 학습했을 때 오류 등으로 학습이 중단될 수 있다. 따라서 이러한 현상을 방지하기 위하여 일정 에폭마다 학습된 결과를 저장해 나중에 이어서 학습하게 할 수 있다.
3.8. 활성화 함수
활성화 함수란 인공 신경망에서 사용되는 은닉층을 활성화하기 위한 함수이다.
여기에서 활성화란 인공 신경망의 뉴런의 출력값을 선형에서 비선형으로 변환하는 것이다.
즉, 활성화 함수는 네트워크가 데이터의 복잡한 패턴을 기반으로 학습하고 결정을 내릴 수 있게 제어한다.
역전파의 측면에서 생각해보면, 비선형 구조에서 나오는 미분값을 통해 학습이 진행될 수 있게 하므로 입력을 정규화하는 과정으로도 볼 수 있다.
3.8.1. 이진 분류(예제 3.56)
규칙에 따라 입력된 값을 두 그룹으로 분류하는 작업
로지스틱 회귀, 논리 분류라고도 부른다.
3.8.2. 시그모이드 함수
$$ sigmoid(x) = {1\over{1+e^{-x}}} $$
시그모이드 함수의 계수가 0에 가까워질수록 완만한 경사를 갖게 된다.
시그모이드함수는 출력값의 범위를 제한하기때문에 기울기 폭주(Exploding Gradient) 문제가 발생하지 않지만 기울기 소실(Vanishing Gradient) 문제를 일으킨다.
3.8.3. 이진 교차 엔트로피
$$ BCE=BCE1+BCE2~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\\=-(Y_ilog{(\hat{Y_i})}+(1-Y_i)log{(1-{\hat{Y_i}})}) $$
기존의 평균 제곱 오차 함수는 명확하게 불일치하는 경우에도 높은 손실 값을 반환하지 않았다.
3.8.4. 비선형 활성화 함수
비선형 활성화 함수는 네트워크에 비선형성을 적용하기 위해 인공 신경망에서 사용되는 함수이다. 입력이 단순한 선형 조합이 아닌 형태로 출력을 생성하는 함수이다.
- 계단함수
- 임곗값 함수
- 시그모이드 함수

$$ sigmoid(x) = {1\over{1+e^{-x}}} $$
- 하이퍼볼릭 탄젠트 함수

$$ Tanh(x)={{e^x-e^{-x}}\over{e^x+e^{-x}}} $$
- ReLU 함수
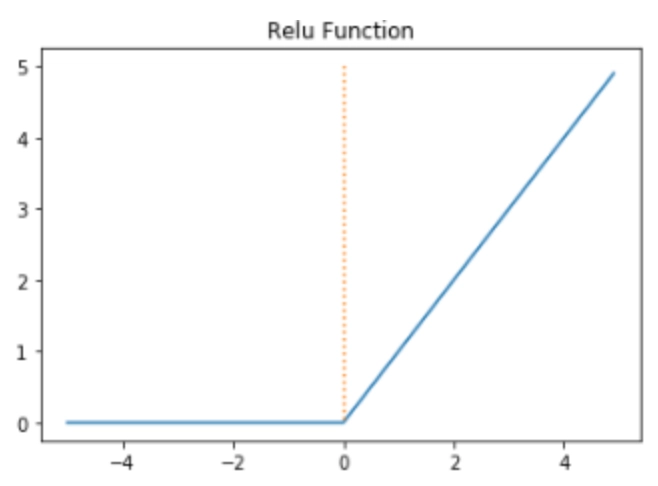
$$ f(x)=max(0,x) $$
- LeakyReLU

$$ f(x)=(ax,x) $$
- PReLU
LeakyReLU와 같지만 a의 값이 고정된 값이 아니라, 학습을 통해 갱신되는 값이다.
- ELU


여기서 a도 PReLU와 같이 학습을 통해 갱신되는 값이다.
- 소프트맥스함수
차원벡터에서 특정 출력값이 k번째 클래스에 속할 확률을 계산한다.

$$ P_k={{e^{z_k}}\over{\sum^n_{i=1}e^{z^i}}} $$
3.9. 순전파와 역전파(예제 3.57)
순전파(Forward Propagation)란 순방향 전달(Forward Pass)이라고도 하며 입력이 주어지면 신경망의 출력을 계산하는 프로세스다.
역전파(Back Propagation)는 순전파 방향과 반대로 연산이 진행된다.
학습 과정에서 네트워크의 가중치와 편향은 예측된 출력값과 실제 출력값 사이의 오류를 최소화하기 위해 조정
순전파와 역전파는 네트워크가 입력값을 기반으로 예측을 수행할 수 있게 한다.
3.10. 퍼셉트론
퍼셉트론이란 인공 신경망의 한 종류이다.
활성화 함수가 계단 함수라면 퍼셉트론이라고 부르고, 계단 함수가 아니라면 인공 신경망으로 부른다.
3.10.1. 단층 퍼셉트론(예제 3.58)
XOR 게이트와 같이 하나의 기울기로 표현하기 어려운 구조에서는 단층 퍼셉트론을 적용하기 어렵다. 따라서 이러한 문제를 해결하기 위해 다층 퍼셉트론을 활용한다.
3.10.2. 다층 퍼셉트론
단층 퍼셉트론(Multi-Layer Perceptron)을 여러 개 쌓아 은닉층을 생성한다.
은닉층을 두 개 이상 연결한다면 심층신경망(Deep Neural Network, DNN)이라 부른다.
은닉층이 늘어날 수록 더 복잡한 구조의 문제를 해결할 수 있다.
(예제 3.57)의 계층 구조가 다층 퍼셉트론을 의미하며 역전파 과정을 통해 모든 노드의 가중치와 편향을 수정해 오차가 작아지는 방향으로 학습이 진행된다.
- 입력층부터 출력층까지 순전파를 진행
- 출력값(예측값)과 실젯값으로 오차 계산
- 오차를 퍼셉트론의 역방향으로 보내면서 입력된 노드의 기여도 측정
- 손실함수를 편미분해 기울기 계산
- 연쇄법칙을 통해 기울기를 계산
- 입력층에 도달할 때까지 노드의 기여도 측정
- 모든 가중치에 최적화 알고리즘 수행
'ML,DL' 카테고리의 다른 글
| [파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습] chapter5 토큰화 (0) | 2026.03.14 |
|---|---|
| [파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습] chapter4 파이토치 심화 (0) | 2026.03.12 |
| RNN, LSTM 이해하기 (PyTorch로 구현한 코드 포함) (0) | 2026.03.11 |
| [바닥부터 배우는 강화학습] Chapter 7 Deep RL 첫 걸음 (0) | 2026.03.11 |
| [바닥부터 배우는 강화학습] Chapter 6 MDP를 모를 때 최고의 정책 찾기 (0) | 2026.03.10 |