4.1. 과대적합과 과소적합
- 과대적합(Overfitting) : 모델이 훈련 데이터 에서는 우수하게 예측하지만, 새로운 데이터에서는 제대로 예측하지 못해 오차가 크게 발생하는 것(모델의 일반화 능력 저하) → 모델이 훈련 데이터에만 적합하게 학습되어 새로운 데이터에 대해서는 성능이 저하되는 경우
- 과소적합(Underfitting) : 모델이 훈련 데이터에서도 성능이 좋지 않고 새로운 데이터에서도 성능이 좋지 않은 것
과대적합과 과소적합은 다음과 같은 공통점이 있다.
- 성능 저하
- 모델 선택 실패 → 모델을 변경하거나 모델 구조를 개선해야한다.
- 편향-분산 트레이드오프 → 모델의 성능을 높이기 위해 편향과 분산의 균형을 맞춰야 한다.
4.1.1. 과대적합과 과소적합 문제 해결
- 데이터 수집 : 학습 데이터 수 늘리기
- 피처 엔지니어링 : 모델이 더 학습하기 쉬운 형태로 데이터를 변환
- 모델 변경
- 조기 중단 : 과대 적합이 발생하기 전에 학습을 중단
- 배치 정규화 : 4.2
- 가중치 초기화 : 4.3
- 정칙화 : 4.4
4.2. 배치정규화
배치 정규화(Batch Normalization) : 내부 공변량 변화(Internal Covariate Shift)를 줄여 과대적합을 방지하는 기술
내부 공변량 변화(계층마다 입력 분포가 변경되는 현상)가 발생하는 경우 은닉층에서 다음 은닉층으로 전달될 때 입력값이 균일해지지 않아 가중치가 제대로 갱신되지 않을 수 있다. 이로 인해 학습이 불안정해지고 느려져 가중치가 일정한 값으로 수렴하기 어려워진다. 또한 초기 가중치 값에 민감해져 일반화하기가 어려워져 더 많은 학습 데이터를 요구하게 된다.
→ 이러한 문제를 해결하기 위해 각 계층에 배치 정규화를 적용한다.
배치 정규화는 미니 배치의 입력을 정규화하는 방식으로 동작한다. 예를 들어, 미니 배치에 전달되는 입력값이 [100,1]이거나 [1, 0.01] 이라면 두 배열의 값 모두 [1.4142, -0.7071]로 정규화한다.
배치 정규화를 적용하면 각 계층에 대한 입력이 일반화되고 독립적으로 정규화가 수행되므로 더 빠르게 값을 수렴할 수 있다. 입력이 정규화되므로 초기 가중치에 대한 영향을 줄일 수 있다.
4.2.1. 정규화 종류
- 배치 정규화 : 미니 배치에서 계산된 평균 및 분산을 기반으로 계층의 입력을 정규화한다. 컴퓨터 비전과 관련된 모델 중 합성곱 신경망(CNN)이나 다층 퍼셉트론(MLP)과 같은 순방향 신경망에서 주로 사용된다.
- 계층 정규화 : 이미지 데이터 전체를 대상으로 정규화를 수행하지 않고 각각의 이미지 데이터에 채널별로 정규화를 수행한다. 자연어 처리에서 주로 사용되며 순환 신경망(RNN)이나 트랜스포머 기반 모델에서 주로 사용된다.
- 인스턴스 정규화 : 채널과 샘플을 기준으로 정규화를 수행한다. 생성적 적대 신경망(GAN)이나 이미지의 스타일을 변환하는 스타일 변환(Style Transfer) 모델에서 주로 사용된다.
- 그룹 정규화 : 채널을 N개의 그룹으로 나누고 각 그룹 내에서 정규화를 수행한다. 합성곱 신경망(CNN)의 배치 크기가 작으면 배치 정규화가 배치의 평균과 분산이 데이터세트를 대표한다고 보기 어렵기 때문에 배치 정규화의 대안으로 사용된다.
4.2.2. 배치 정규화 풀이
$$ y_i={{x_i-E[X]}\over{\sqrt{Var[X]}+\varepsilon}}*\gamma+\beta $$
$x_i$ : 입력값, $y_i$ : 배치 정규화가 적용된 결괏값 $E[X]$ : 산술 평균, $Var[X]$ : 분산, $X$ : 전체 모집단 $\varepsilon$ : 분모가 0이 되지않도록 하는 상수($10^{-5}(0.00001)$), $\gamma$, $\beta$ : 학습 가능한 매개변수
아래와 같은 텐서에서 배치 정규화를 적용해보자
#예제 4.1 텐서 초깃값
x = torch.FloatTensor([[0.6577, -0.5797, 0.6360],
[0.7392, 0.2145, 1.523],
[0.2432, 0.5662, 0.322]])
위의 FloatTensor를 수식으로 표현하면 아래와 같다.
$$ X_1=[0.6577, -0.5797, 0.6360]\\X_2=[0.7392, 0.2145, 1.523]\\X_3=[0.2432, 0.5662, 0.322] $$
각 $X_n$에 배치 정규화를 하여 $Y_n$을 구하면 아래와 같다.
$$ Y_1=[-1.3246, 1.0912, 02334]\\Y_2=[-1.3492,0.3077,1.0415]\\Y_3=[-0.3756,1.3685,-0.9930] $$
코드를 통해 배치 정규화를 하면 간단하게 배치 정규화 클래스를 통해 수행할 수 있다.
#예제 4.2 배치 정규화 수행
import torch
from torch import nn
x = torch.FloatTensor([[0.6577, -0.5797, 0.6360],
[0.7392, 0.2145, 1.523],
[0.2432, 0.5662, 0.322]])
print(nn.BatchNorm1d(3)(x))
#예제 4.3 배치 정규화 클래스
m = torch.nn.BatchNorm1d(num_features, eps=1e-05)
4.3. 가중치 초기화(예제 4.3, 4.4)
**가중치 초기화(Weight Initialization)**란 모델의 초기 가중치 값을 설정하는 것이다. 모델 매개변수에 적절한 초깃값을 설정한다면 기울기 폭주나 기울기 소실 문제를 완화할 수 있다.
4.3.1. 상수 초기화
초기 가중치 값을 모두 같은 상숫값으로 초기화한다.
구현이 간단하고 계산 비용이 많이 들지 않지만, 일반적으로 사용되지 않는 초기화 방법이다.
4.3.2. 무작위 초기화
초기 가중치의 값을 무작위 값이나 특정 분포 형태로 초기화 하는 것을 말한다.
노드의 가중치와 편향을 무작위로 할당해 네트워크가 학습할 수 있게 하여 대칭 파괴 문제를 방지할 수 있다. 간단하고 많이 사용되는 방법이지만, 계층이 많아지고 깊어질수록 기울기 소실 현상이 발생한다.
4.3.3. 제이비어&글로럿 초기화
균등 분포나 정규 분포를 사용해 가중치를 초기화하는 방법이다. 각 노드의 출력 분산이 입력 분산과 동일하게 하도록 가중치를 초기화한다.
- 제이비어 초기화(균등 분포)
$$ W=U(-a.a)\\a=gain*\sqrt{{6}\over{fan_{in}+fan_{out}}} $$
- 제이비어 초기화(정규 분포)
$$ W=N(0,std^2)\\std=gain*\sqrt{{2}\over{fan_{in}+fan_{out}}} $$
제이비어 초기화는 입력 데이터의 분산이 출력 데이터에서 유지되도록 가중치를 초기화하므로 시그모이드나 하이퍼볼릭 탄젠트를 활성화 함수로 사용하는 네트워크에서 효과적이다.
4.3.4. 카이밍&허 초기화
제이비어 초기화 방법과 마찬가지로 균등 분포나 정규 분포를 사용해 가중치를 초기화하는 방법이다.
- 카이밍 초기화(균등 분포)
- $$ W=U(-a.a)\\a=gain*\sqrt{{3}\over{fan_{in}}} $$
- 카이밍 초기화(정규 분포)
$$ W=N(0,std^2)\\std={gain\over\sqrt{fan_{in}}} $$
각 노드의 출력 분산이 입력 분산과 동일하게 만들어 ReLU 함수의 죽은 뉴런 문제를 최소화할 수 있다. 그러므로 ReLU를 활성화 함수로 사용하는 네트워크에서 효과적이다.
4.3.5. 직교 초기화
특잇값 분해(SVD)를 활용해 자기 자신을 제외한 나머지 모든 열, 행 벡터들과 직교이면서 동시에 단위 벡터인 행렬을 만드는 방법이다. 장단기 메모리(LSTM) 및 게이트 순환 유닛(GRU)과 같은 순환 신경망(RNN)에서 주로 사용된다.
직교 초기화는 모델이 특정 초기화 값에 지나치게 민감해지므로 순방향 신경망에서는 사용하지 않는다.
4.4. 정칙화
정칙화(Regularization)란 모델 학습 시 발생하는 과대적합 문제를 방지하기 위해 사용되는 기술로, 모델이 암기가 아니라 일반화를 할 수 있도록 손실함수에 규제를 가하는 방식이다.
모델이 특정 피처나 특정 패턴에 너무 많은 비중을 할당하지 않도록 손실 함수에 규제를 가해 모델의 일반화 성능(Generalization Performance)을 향상시킨다.
정칙화는 모델이 비교적 복잡하고 학습에 사용되는 데이터의 수가 적을 때 활용한다.
4.4.1. L1 정칙화
L1 정칙화(L1 Regularization)는 라쏘 정칙화(Lasso Regularization)라고도 하며 L1 노름 방식을 사용해 규제하는 방법이다.
이러한 방식을 차용해 L1 정칙화는 손실 함수에 가중치의 절댓값을 추가해 과대적합을 방지한다.
모델 학습 시 값이 크지 않은 가중치들은 0으로 수렴하게 되어 예측에 필요한 특징의 수가 줄어들고 예측 불필요한 가중치가 0이 되므로 L1 정칙화를 적용한 모델은 특징 선택(Feature Selection) 효과를 얻을 수 있다.
$\lambda$는 규제 강도로 너무 많거나 적은 규제를 가하지 않게 조절하는 하이퍼파라미터이다.(0보다 큰 값)
L1 정칙화는 주로 선형 모델에 적용하며, 선형 모델에 L1 정칙화를 적용하는 것을 라쏘 회귀라고 한다.
$$ L_1=\lambda*\sum^n_{i=0}|w_i| $$
#예제 4.5 L1 정칙화 적용 방식
for x, y in train_dataloader:
x = x.to(device)
y = y.to(device)
output = model(x)
_lambda = 0.5
l1_loss = sum(p.abs().sum() for p in model.parameters())
loss = criterion(output,y) + _lambda * l1_loss
4.4.2. L2 정칙화
L2 정칙화(L2 Regularization)는 릿지 정칙화(Ridge Regularization)라고도 하며 L2 노름을 이용해 규제하는 방법이다.
이러한 방식을 차용해 L2 정칙화는 손실 함수에 가중치 제곱의 합을 추가해 과대적합을 방지한다.
하나의 특징이 너무 중요한 요소가 되지 않도록 규제한다.
가중치들이 비교적 균일하게 분포되며, 가중치를 0으로 만들지 않고 0에 가깝게 만든다.
모델 학습 시 오차를 최소화하면서 가중치를 작게 유지하고 골고루 분포되게끔 하므로 모델의 복잡도가 일부 조정된다.
$$ L_2=\lambda*\sum^n_{i=0}|w_i^2| $$
#예제 4.6 L2 정칙화 적용 방식
for x, y in train_dataloader:
x = x.to(device)
y = y.to(device)
output = model(x)
_lambda = 0.5
l2_loss = sum(p.pow(2.0).sum() for p in model.parameters())
loss = criterion(output,y) + _lambda * l2_loss
4.4.3. 가중치 감쇠
가중치 감쇠(Weight Decay)는 손실함수에 규제 항을 추가하는 기술을 의미한다.
하지만 파이토치나 텐서플로와 같은 딥러닝 라이브러리에서는 이 용어가 최적화 함수에 적용하는 L2 정규화의 의미로 사용된다.
optimizer = torch.optim.SGD(model.parameters(),lr=0.01, weight_decay = 0.01)
4.4.5. 모멘텀
모멘텀(Momentum)은 경사 하강법 알고리즘의 변형 중 하나로, 지수 가중 이동평균을 사용하며, 이전 기울기 값의 일부를 현재 기울기 값에 추가해 가중치를 갱신한다.
이전 기울기 값에 의해 설정된 방향으로 더 빠르게 이동하므로, 일종의 관성(Momentum) 효과를 얻을 수 있다.
$$ v_i=\gamma{v_{i-1}}+\alpha{\nabla{f(W_i)}}\\W_{i+1}=W_i-v_i $$
$v_i$ : i번째 모멘텀(이동 벡터), $\gamma$ : 모멘텀 계수(하이퍼파라미터)
4.4.6. 엘라스틱 넷
엘라스틱 넷은 L1 정칙화와 L2 정칙화를 결합해 사용하는 방식이다. L1 정칙화는 모델이 희박한 가중치를 갖게 규제하는 반면, L2 정칙화는 큰 가중치를 갖지 않게 규제한다. 이 두 정칙화 방식을 결합함으로써 희소성과 작은 가중치의 균형을 맞춘다.
$$ Elastic-Net=\alpha*L_1+(1-\alpha)*L_2 $$
$\alpha$ : 혼합 비율(0~1)
혼합 비율을 1로 사용하면 L1 정칙화가 되며, 0으로 사용하면 L2 정칙화가 된다.
→ 트레이드오프 문제를 더 유연하게 대처할 수 있다.
4.4.7. 드롭아웃
모델의 훈련 과정에서 일부 노드를 일정 비율로 제거하거나 0으로 설정해 과대적합을 방지하는 간단하고 효율적인 방법이다.
과대적합을 발생기키는 이유 중 하나는 모델 학습 시 발생하는 노드 간 동조화(Co-adaptation) 현상이다. 동조화 현상이란 모델 학습 중 특정 노드의 가중치나 편향이 큰 값을 갖게 되면 다른 노드가 큰 값을 갖는 노드에 의존하는 것을 말한다. 이러한 현상은 특정 노드에 의존성이 생겨 학습 속도가 느려지고 새로운 데이터를 예측하지 못해 성능을 저하시킬 수 있다.
모델이 일부 노드를 제거해 학습하므로 투표(Voting)효과를 얻을 수 있어 모델 평균화(Model Averaging)가 된다. 하지만 모델 평균화 효과를 얻기 위해 다른 드롭아웃 마스크를 사용해 모델을 여러 번 훈련해야 하므로 훈련 시간이 늘어난다. 따라서, 드롭아웃을 적용할 때는 충분한 데이터 세트와 비교적 깊은 모델에 적용한다.
from torch import nn
class Net(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(10,10)
self.dropout = nn.Dropout(p=0.5)
self.layer2 = nn.Linear(10,10)
def forward(self,x):
x = self.layer(x)
x = self.dropout(x)
x = self.layer2(x)
return x
p는 베르누이 분포의 모수를 의미하며 이 분포로 각 노드의 제거 여부를 확률적으로 선택한다.
드롭아웃은 일반적으로 배치 정규화와 동시에 사용하지 않으므로 다른 기법을 동시에 적용할 때 주의해서 적용한다. 드롭아웃과 배치 정규화는 서로의 정칙화 효과를 방해할 수 있다. 그러므로 드롭아웃과 배치정규화를 사용하는 경우에는 드롭아웃, 배치 정규화 순으로 적용한다.
4.4.8. 그레이디언트 클리핑
그레이디언트 클리핑(Gradient Clipping)은 모델을 학습할 때 기울기가 너무 커지는 현상을 방지하는데 사용되는 기술이다.
과대적합 모델은 특정 노드의 가중치가 너무 크다는 특징을 갖는데 높은 가중치는 높은 분산값을 갖게 하여 모델의 성능이 저하될 수 있다.($\because$모델의 가중치가 높다는 것은 해당 모델 파라미터가 출력에 미치는 영향이 크다는 것이므로 노이즈나 비교적 불필요한 패턴까지 학습할 수 있음)
이러한 현상을 방지하기 위해 가중치 최댓값을 규제해 최대 임곗값을 초과하지 않도록 기울기를 잘라(Clipping) 설정한 임곗값으로 변경한다.
$$ w=r{w\over{||w||}} ~~ if :||w||>r~~~~~(최대~임곗값 : r) $$
#예제 4.9 그라디언트 클리핑 함수
grad_norm = torch.nn.utils.clip_grad_norm(
parameters,
max_norm,
norm_type=2.0
)
# 적용 방식
for x, y in train_dataloader:
x = x.to(device)
y = y.to(device)
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1)
optimizer.step()
그레이디언트 클리핑은 순환 신경망(RNN)이나 LSTM 모델을 학습하는 데 주로 사용된다.
4.5. 데이터 증강 및 변환
데이터 증강(Data Augmentation)이란 데이터가 가진 고유한 특징을 유지한 채 변형하거나 노이즈를 추가해 데이터세트의 크기를 인위적으로 늘리는 방법이다.
강건한 모델을 구축하기 위한 가장 중요한 요소는 학습 데이터의 수와 품질이다. 하지만 데이터 수집은 다양한 이유로 인해 어려운 상황에 직면할 수 있다. 그러므로 기존 학습 데이터를 재가공해 원래 데이터와 유사하지만 새로운 데이터를 생성할 수 있다.
4.5.1. 텍스트 데이터
텍스트 데이터 증강은 문서 분류 및 요약, 문장 변역과 같은 자연어 처리 모델을 구성할 때 데이터세트의 크기를 쉽게 늘리기 위해 사용된다.
자연어 처리 데이터 증강(NLPAUG) 라이브러리를 활용해 텍스트 데이터를 증강한다.
- 삽입 및 삭제
#예제 4.10 단어 삽입
import nlpaug.augmenter.word as naw
texts = ["Those who can imagine anything can create the impossible.",
"We can only see a short diatance ahead, but we can see plenty there that needs to be done.",
"If a machine is expected to be infaillible, it cannot also be intelligent."]
aug = naw.ContextualWordEmbsAug(model_path = "bert-base-uncased", action = "insert")
augmented_text = aug.augment(texts)
for text, augmented in zip(texts, augmented_texts):
print(f"src : {text}")
print(f"dst : {augmented}")
print("------------------")
#예제 4.11 문자 삭제
import nlpaug.augmenter.char as nac
texts = ["Those who can imagine anything can create the impossible.",
"We can only see a short diatance ahead, but we can see plenty there that needs to be done.",
"If a machine is expected to be infaillible, it cannot also be intelligent."]
aug = nac.ContextualWordEmbsAug(action = "delete")
augmented_text = aug.augment(texts)
for text, augmented in zip(texts, augmented_texts):
print(f"src : {text}")
print(f"dst : {augmented}")
print("------------------")
- 교체 및 대체
교체는 단어나 문자의 위치를 교환하는 방법이고, 대체는 단어나 문자를 임의의 단어나 문자로 바꾸거나 동의로 변경하는 방법을 의미한다.
#예제 4.12 단어 교체
import nlpaug.augmenter.word as naw
texts = ["Those who can imagine anything can create the impossible.",
"We can only see a short diatance ahead, but we can see plenty there that needs to be done.",
"If a machine is expected to be infaillible, it cannot also be intelligent."]
aug = naw.RandomWordAug(action = "swap")
augmented_text = aug.augment(texts)
for text, augmented in zip(texts, augmented_texts):
print(f"src : {text}")
print(f"dst : {augmented}")
print("------------------")
#예제 4.13 단어 대체1
import nlpaug.augmenter.word as naw
texts = ["Those who can imagine anything can create the impossible.",
"We can only see a short diatance ahead, but we can see plenty there that needs to be done.",
"If a machine is expected to be infaillible, it cannot also be intelligent."]
aug = naw.SynonymAug(aug_src="wordnet")
augmented_text = aug.augment(texts)
for text, augmented in zip(texts, augmented_texts):
print(f"src : {text}")
print(f"dst : {augmented}")
print("------------------")
#예제 4.14 단어 대체2
import nlpaug.augmenter.word as naw
texts = ["Those who can imagine anything can create the impossible.",
"We can only see a short diatance ahead, but we can see plenty there that needs to be done.",
"If a machine is expected to be infaillible, it cannot also be intelligent."]
reserved_tokens = [["can","can't","cannot","could"],]
reserved_aug = naw.ReservedAug(reserved_tokens = reserved_tokens)
augmented_texts = reserved_aug.augment(texts)
for text, augmented in zip(texts, augmented_texts):
print(f"src : {text}")
print(f"dst : {augmented}")
print("------------------")
- 역변역
역변역(Back-translation)이란 입력 텍스트를 특정 언어로 변역한 다음 다시 본래의 언어로 변역하는 방법을 의미한다.
#예제 4.15 역변역
import nlpaug.augmenter.word as naw
texts = ["Those who can imagine anything can create the impossible.",
"We can only see a chort diatance ahead, but we can see plenty there that needs to be done.",
"If a machine is expected to be infaillible, it cannot also be intelligent."]
back_translation = naw.BackTranslationAug(
from_model_name = "facebook/wmt19-en-de",
to_model_name = "facebook/wmt19-de-en")
)
augmented_texts = back_translation.augment(texts)
for text, augmented in zip(texts, augmented_texts):
print(f"src : {text}")
print(f"dst : {augmented}")
print("------------------")
4.5.2. 이미지데이터
이미지 데이터 증강은 객체 검출 및 인식, 이미지 분류와 같은 이미지 처리 모델을 구성할 때 데이터세트의 크기를 쉽게 늘리기 위해 사용된다.
- 변환 적용 방법(예제 4.16)
transforms.ToTensor는 PIL.Image 형식을 Tensor 형식으로 변환한다. 텐서화 클래스는 [0~255] 범위의 픽셀값을 [0.0~1.0] 사이의 값으로 최대최소정규화를 수행한다. 또한 입력 데이터의 [높이, 너비, 채널] 형태를 [채널, 높이, 너비] 형태로 반환한다.
- 회전 및 대칭(예제 4.17)
- 자르기 및 패딩(예제 4.18)
- 크기 조정(예제 4.19)
- 변형(예제 4.20)
기하학적 변환을 통해 이미지를 변경한다. 기하학적 변환은 크게 아핀 변환과 원근 변환이 있다.
- 색상 변환(예제 4.21)
명도(brightness), 대비(contrast), 채도(saturation), 색상(hue)을 변환한다.
- 노이즈(예제 4.22)
특정 픽셀 값에 편향되지 않도록 임의의 노이즈를 추가해 모델의 일반화 능력을 높이는 데 사용된다.
- 컷아웃 및 무작위 지우기(예제 4.23)
- 혼합 및 컷믹스(예제 4.24)
컷믹스는 이미지 패치 영역에 다른 이미지를 덮어씌우는 방법이다. 이미지영역을 잘라내고 붙여넣기 하는 방법으로 볼 수 있다.
4.6. 사전 학습된 모델
사전 학습된 모델(Pre-trained Model) : 대규모 데이터세트로 학습된 딥러닝 모델로 이미 학습이 완료된 모델
사전 학습된 모델 자체를 현재 시스템에 적용하거나 사전 학습된 *임베딩(Embeddings)벡터를 활용해 모델을 구성할 수 있다.
*입력 데이터를 연속적이고 조밀한 벡터로 매핑하는 것. 예를 들어 cat이라는 단어를 [0.123,…]와 같이 매핑
4.6.1. 백본
백본(Backbone) : 입력 데이터에서 특징을 추출해 최종 분류기에 전달하는 딥러닝 모델이나 딥러닝 모델의 일부
백본 네트워크는 입력 데이터에서 특징을 추출하므로 노이즈와 불필요한 특성을 제거하고 가장 중요한 특징을 추출할 수 있다. 이렇게 추출된 특징을 활용해 새로운 모델이나 기능의 입력으로 사용한다.
이미지에서 객체를 검출하는 합성곱 신경망은 초기 계층(하위 계층)에서 점이나 선과 같은 저수준의 특징을 학습하고 중간 계층에서 객체나 형태를 학습한다. 최종 계층(상위 계층)에서는 이전 계층의 특징을 기반으로 객체를 이해하고 검출한다. 객체 검출 모델이 아닌 포즈 추정 모델이나 이미지 분할(Image Segmentation)모델로 확장하려고 한다면, 모델을 처음부터 구성하는 것이 아니라 객체를 검출하는 합성곱 신경망의 특징값을 가져와 최종 계층을 바꿔 기존 모델과 다른 모델을 구성할 수 있다.
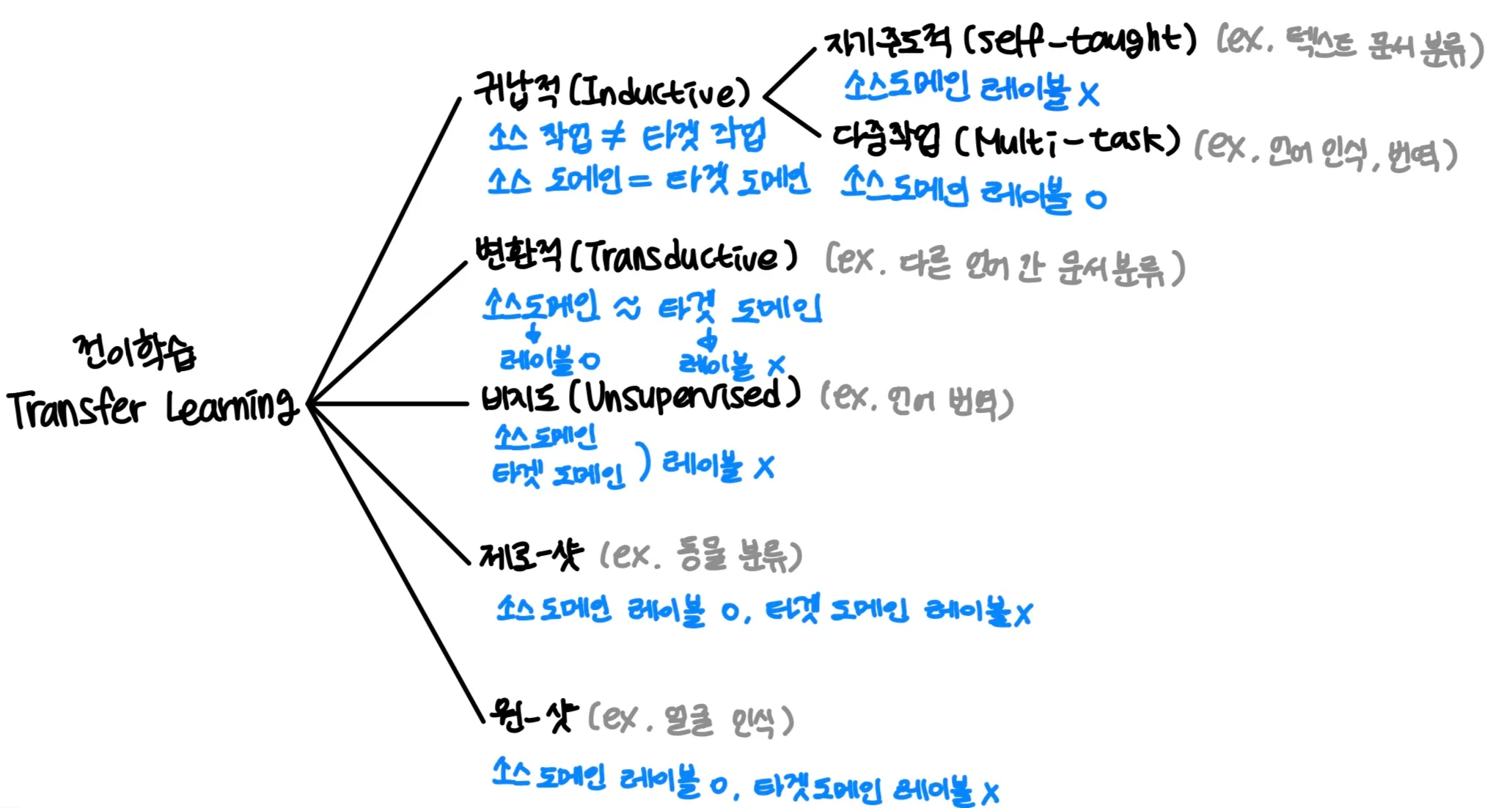
4.6.2. 전이 학습
어떤 작업을 수행하기 위해 이미 사전 학습된 모델을 재사용해 새로운 작업이나 관련 도메인의 성능을 향상시킬 수 있는 기술
→ 소스 도메인(Source Domain)에서 학습한 지식을 활용해 타깃 도메인(Target Domain)에서 모델의 성능을 향상시키는 것
전이 학습은 사전 학습된 모델과 미세 조정된 모델의 관계를 설명하기 위해 업스트림(Upstream)과 다운스트림(Downstream) 영역으로 구별된다.

- 귀납적 전이 학습(Inductive Transfer Learning) : 소스 작업과 타겟 작업이 다르지만 소스 도메인과 타겟 도메인이 같은 경우
- 자기주도적 학습(Self-taught Learning) : 소스 도메인에서 레이블이 지정된 데이터의 수가 매우 적거나 없을 때 사용하는 방법이다. 오토 인코더와 같은 모델을 통해 특징을 추출하고 적은 양이더라도 타깃 도메인에 있는 ‘레이블이 지정된 데이터’를 통해 타겟 작업을 한다.
- 다중 작업 학습(Multi-task Learning) : 레이블이 지정된 소스 도메인과 타깃 도메인 데이터를 기반으로 모델에 여러 작업을 동시에 가르치는 방법을 의미한다. 다중 작업 학습의 모델 구조는 공유 계층과 작업별 계층으로 나뉜다.
- 공유 계층(Shared Layers) : 소스 도메인과 타깃 도메인의 데이터 세트에서 모델을 사전 학습한 다음 작업별 계층마다 타깃 도메인 데이터세트로 미세 조정하는 방법으로 모델을 구성한다.
- 작업별 계층(Task Specific Layer)
- 변환적 전이 학습(Transductive Transfer Learning) : 소스 도메인과 타깃 도메인이 유사하지만 완전히 동일하지 않은 경우 레이블이 지정된 소스 도메인으로 사전 학습된 모델을 구축하며, 레이블이 지정되지 않은 타깃 도메인으로 모델을 미세 조정해 특정 작업에 대한 성능을 향상시킨다.
- 도메인 적응(Domain Adaption) : 소스 도메인과 타깃 도메인의 특징 분포를 전이시키는 방법
- 표본 선택 편향/공변량 이동(Sample Selection Bias/Covariance Shift) : 소스 도메인과 타깃 도메인의 분산과 편향이 크게 다를 때 표본을 선택해 편향이나 공변량을 이동시키는 방법
- 비지도 전이 학습(Unsupervised Transfer Leanring) : 소스 도메인과 타깃 도메인 모두 레이블이 지정된 데이터가 없는 경우 소스 도메인에서 얻은 지식을 타깃 도메인에 적용하는 데 초점을 맞춘다.
- 제로-샷 전이 학습(Zero-shot Transfer Learning) : 사전 학습된 모델을 이용해 다른 도메인에서도 적용할 수 있는 전이 학습 기법 새로운 도메인에서 학습 데이터가 부족한 경우에 유용하게 사용할 수 있다.
- 원-샷 전이 학습(One-shot Transfer Learning) : 한번에 하나의 샘플만을 사용해 모델을 학습하는 방법 매우 적은 양의 데이터를 이용하여 분류 문제를 해결할 수 있다.
- 서포트 셋(Support Set) : 학습에 사용될 클래스의 대표 샘플
- 쿼리 셋(Query Set) : 새로운 클래스를 분류하기 위한 입력 데이터로 분류 대상 데이터
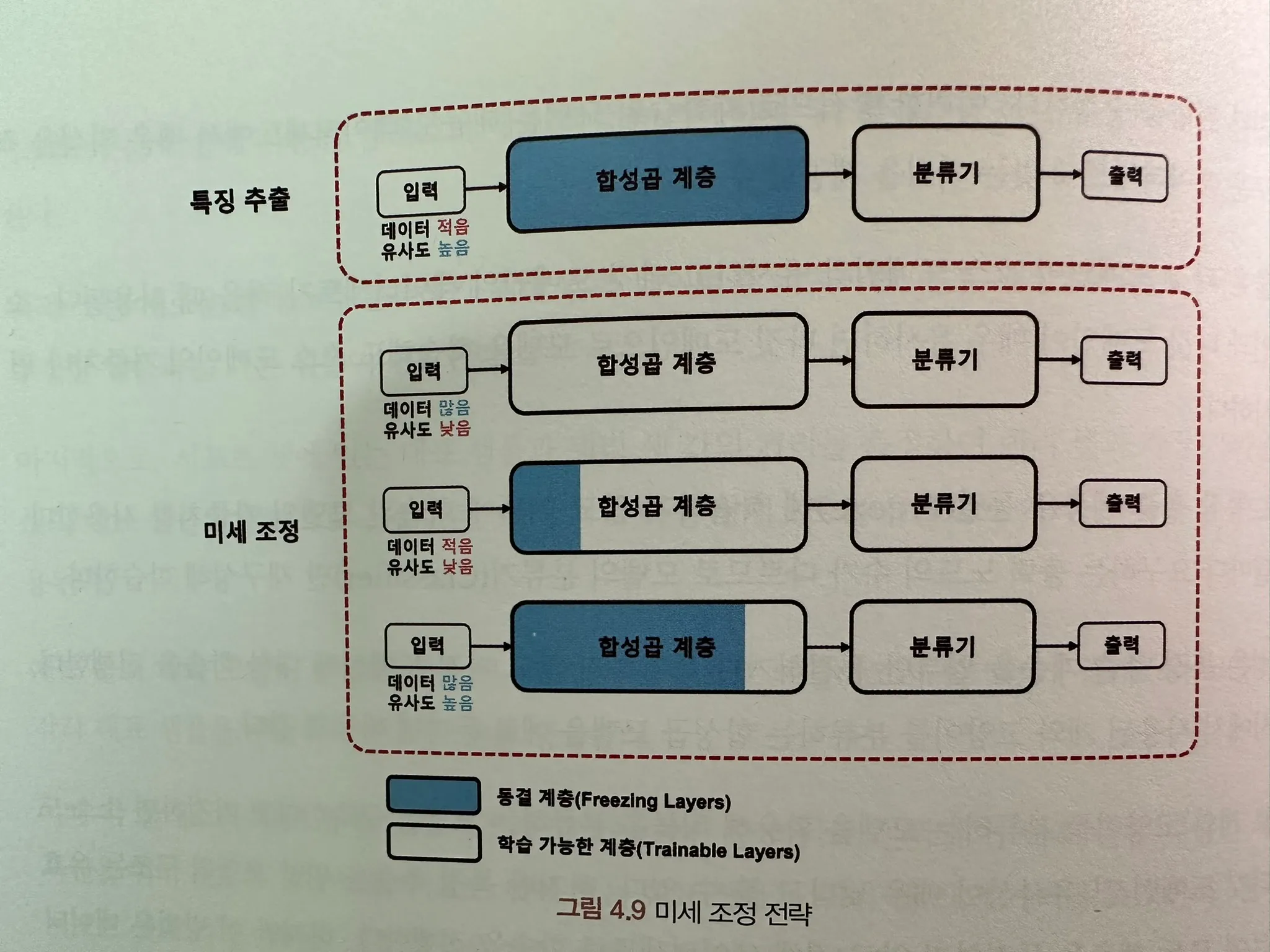
4.6.3. 특징 추출 및 미세 조정
데이터의 개수와 유사성에 따라 미세 조정 전략이 달라진다.

- 특징 추출(Feature Extraction) : 소스 도메인 $\simeq$ 타깃 도메인 ,타깃 도메인 데이터 개수$\downarrow$ 소스 도메인과 타깃 도메인이 매우 유사 → 타깃 도메인으로 모델을 학습해도 소스 도메인의 가중치, 편향 유사 → 데이터가 적은데 유사도가 높으므로 적은 데이터를 활용하기 위해 분류기 학습 O,합성곱 계층 학습X → 특징 추출 계층은 동결(Freeze)해 학습하지 않고 기존에 학습된 모델의 가중치를 사용
- 미세 조정(Fine-tuning) : 특징 추출 계층을 일부만 동결하거나 동결하지 않고 타깃 도메인에 대한 학습을 진행한다.
- 데이터 $\uparrow$, 유사도 $\downarrow$ 데이터가 가진 특징이 다르기 때문에 분류기를 포함한 모델 매개변수를 다시 학습 예) 개와 고양이를 분류하는 모델을 활용해 식물을 분류하는 모델을 구축한다고 가정
- 데이터 $\downarrow$,유사도 $\downarrow$ 도메인 간 유사성 낮지만 하위 계층에서 저수준의 특징을 학습할 때 동일한 특징으로 학습될 가능성 높음 → 초기 계층의 저수준 특징 추출기능을 동결하고 나머지 계층과 분류기를 학습 예) 식물을 분류하는 모델인데 데이터의 크기가 작다고 가정
- 데이터$\uparrow$, 유사도 $\uparrow$ 분류기에 가장 큰 영향을 미치는 상위 계층과 분류기를 학습 소스 도메인과 타깃 도메인이 서로 유사하다고 해도 완전히 동일한 도메인은 아니기때문에 상위 계층의 특징은 다를 수밖에 없다. 이때는 모델의 성능을 최대한 끌어내기 위해 상위계층을 학습 범위에 포함시킨다.
- 데이터 $\downarrow\downarrow\downarrow\downarrow$, 유사도 $\uparrow$ 도메인 간 유사성이 높으면 특징 추출 방법으로 학습할 수 있음 but, 데이터 세트가 충분히 많지 않으므로 상위 계층으로 가면서 특징이 달라짐 → 하위 계층을 동결하고 일부 상위 계층을 학습하는 방법으로 모델 구축
'ML,DL' 카테고리의 다른 글
| [파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습] chapter5 토큰화 (0) | 2026.03.14 |
|---|---|
| [파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습] chapter3 파이토치 기초 (0) | 2026.03.12 |
| RNN, LSTM 이해하기 (PyTorch로 구현한 코드 포함) (0) | 2026.03.11 |
| [바닥부터 배우는 강화학습] Chapter 7 Deep RL 첫 걸음 (0) | 2026.03.11 |
| [바닥부터 배우는 강화학습] Chapter 6 MDP를 모를 때 최고의 정책 찾기 (0) | 2026.03.10 |